User Guide¶
This guide aims to introduce VASCA’s basic functionality and central building blocks of the package’s internals. Good understanding of the latter will help expanding VASCA to more instruments. For more detailed guides and descriptions see the respective API reference, tutorials and Jupyter examples on post-processing listed here.
Intro¶
VASCA is based on a very simple data model as you can see illustrated by the image below. Photometric detections from repeated observations (visits) are taken as input. They must be associated to a uniquely defined patch on the sky, a field. These detections are then clustered on the field level to form uniquely defined sources. Multiple fields are combined to form a region. Overlapping fields undergo a second clustering step to assure the uniqueness of sources also on the region level. The final output of VASCA, the variable source catalog, is based on variability detection, cross-matching and classification of the region-level sources.
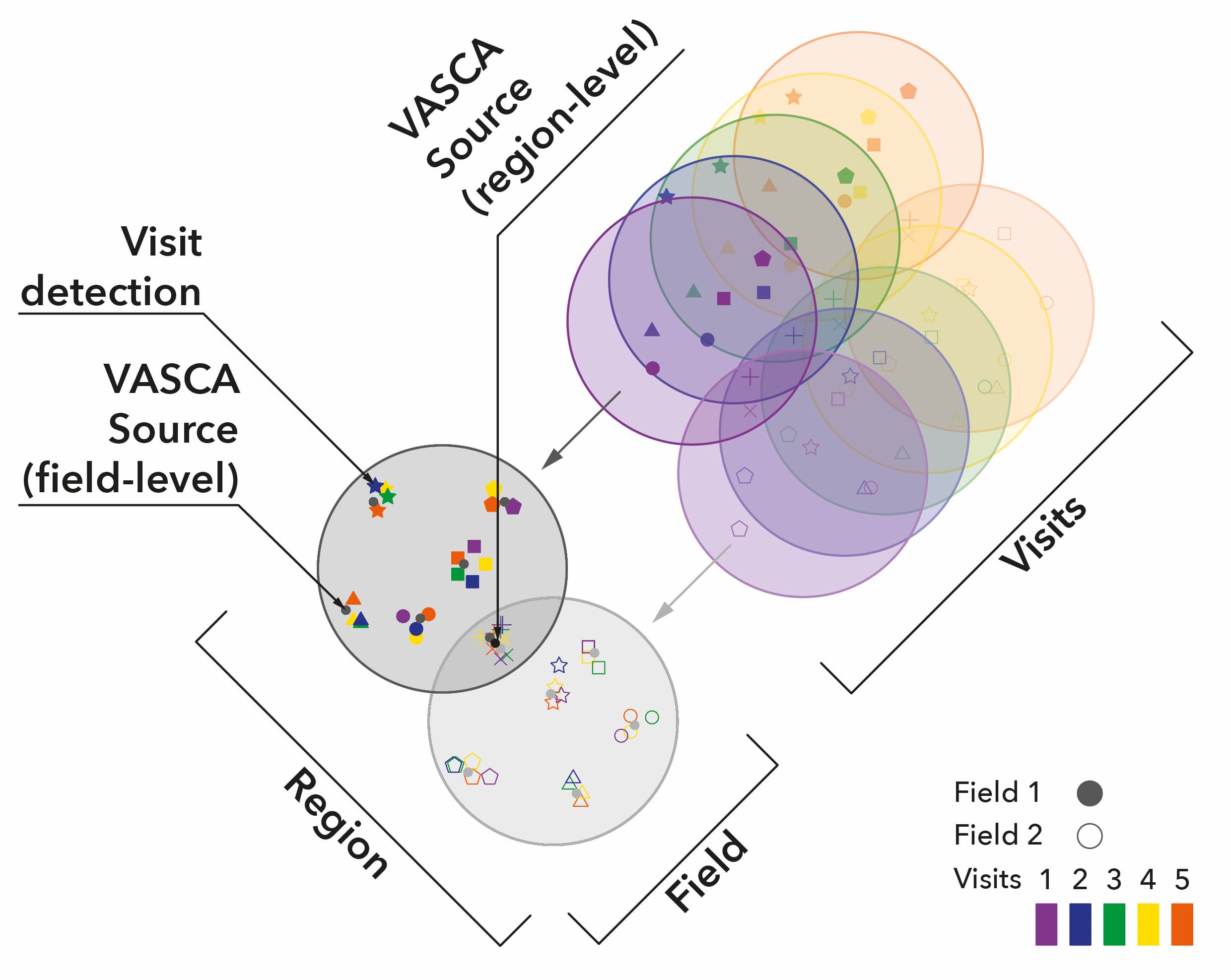
The VASCA data model.¶
On the implementation side, VASCA provides three main data objects that inherit VASCA’s
base data structure, the TableCollection:
SourceUnique cosmic source with an ID, sky coordinates, and a (multi-wavelength) light curve from which variability parameters are computed in addition to possible IDs associating the source to known objects from external catalogs.
BaseFieldUnique field defined on a sky area which holds all sources including their multi-visit detections. Note that a field is uniquely specific in the instrument and the filter (band-pass) it used to make the observation.
RegionRegion on the sky composed of multiple fields where sources are combined from observations in different filters and instruments.
Instrument independence
VASCA’s instrument independence is largely owed to the fact that BaseField is indeed
specific to a given instrument and filter. This allows to treat field-level processing in
parallel and allows instrument- and filter-specific configuration of the pipeline.
Expanding VASCA to new instruments
The only task required to expand VASCA to operate on data for a new instrument is to
create its own field class. This is necessary in order to map observational parameters
like flux, spatial coordinates and their uncertainties to the corresponding parameters in
VASCA. Fields my include co-added sky maps, or intensity images, as reference images and
also visit-level images. The field class must also provide a load() method which
handles data I/O together with the ResourceManager.
All objects inheriting from TableCollection can be written to storage as FITS
files. These hold images and tables compatible with the FITS version 4.0 standard so that
users my use tools like DS9 and
TOPCAT for data exploration and debugging.
To see what kind of Tables are stored in VASCA’s data structures, see the glossary here.
Using VASCA¶
More detailed information on using the package is provided on separate pages, listed below.